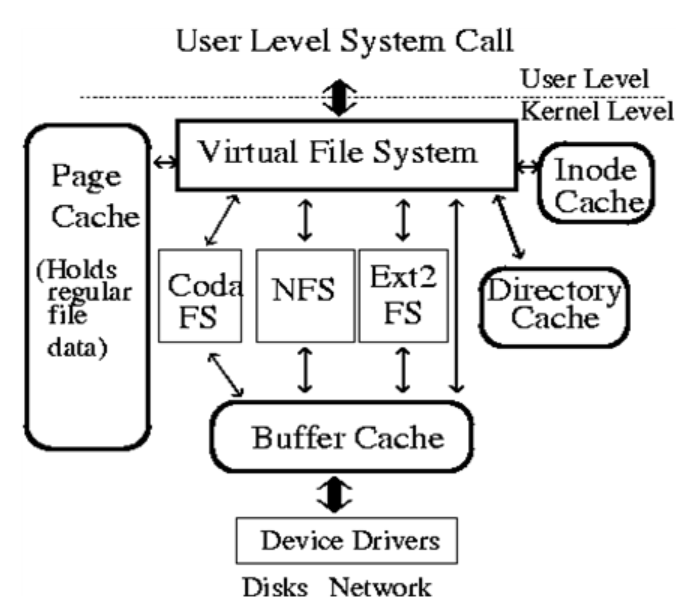
blktrace는 사용자 큐까지 요청 큐 조작에 대한 자세한 정보를 제공하는 블록 계층 IO 추적 메커니즘입니다.
- 커널 패치 커널 이벤트 로깅 인터페이스를 포함하는 Linux 커널에 대한 패치와 이벤트 추적을 생성하기 위해 블록 계층 내의 영역에 패치합니다.
- blktrace 커널에서 이벤트 추적을 장기 온 디스크 스토리지로 전송하거나 blkparse를 통해 직접 형식화 된 출력을 제공하는 유틸리티입니다.
- blkparse 파일에 저장된 이벤트를 형식화하거나 라이브 모드에서 실행할 때 blktrace에 의해 수집 된 데이터를 직접 출력하는 유틸리티입니다.

보이는 바와 같이 Block I/O Layer 단에서 발생하는 이벤트를 CPU 단위로 tracing을 하게 되고 blktrace -> blkparse -> btt -> seekwatcher로 이용해서 분석하게 됩니다.
blkparser : blktrace를 통해 발생하는 CPU별 바이너리 코드 Parsing 해주는 도구 입니다.
btt : btt는 blktrace라는 블록 계층 IO 추적 도구의 사후 처리 도구입니다.
seekwatcher : blktrace내용을 그림(png) 형냍로 분석해주는 도구
blktrace 사용법
| # blktrace -d /dev/sdp -o trace -w 10 === sdp === CPU 0: 8780 events, 412 KiB data CPU 1: 3173 events, 149 KiB data CPU 2: 3600 events, 169 KiB data CPU 3: 1445 events, 68 KiB data CPU 4: 4604 events, 216 KiB data CPU 5: 3764 events, 177 KiB data CPU 6: 1152 events, 54 KiB data CPU 7: 1142 events, 54 KiB data CPU 8: 335 events, 16 KiB data CPU 9: 936 events, 44 KiB data CPU 10: 1470 events, 69 KiB data CPU 11: 385 events, 19 KiB data Total: 30786 events (dropped 0), 1444 KiB data |
Blkparsing 사용법
|
#blkparse -i trace.blktrace.* -d sdp.bin ...
|
Btt 사용법
| # btt -i sdp.bin | more ==================== All Devices ==================== ALL MIN AVG MAX N --------------- ------------- ------------- ------------- ----------- Q2Q 0.000002693 0.002064896 0.224947065 4832 Q2G 0.000000289 0.000010970 0.010791768 57996 G2I 0.000000214 0.000000961 0.000033457 57996 I2D 0.000000160 0.000005564 0.005938405 57108 D2C 0.000135164 0.003013303 0.035674715 4805 Q2C 0.000168496 0.003040692 0.035678620 4828 ==================== Device Overhead ==================== DEV | Q2G G2I Q2M I2D D2C ---------- | --------- --------- --------- --------- --------- ( 8,240) | 4.3338% 0.3797% 0.0000% 2.1643% 98.6272% ---------- | --------- --------- --------- --------- --------- Overall | 4.3338% 0.3797% 0.0000% 2.1643% 98.6272% ==================== Device Merge Information ==================== DEV | #Q #D Ratio | BLKmin BLKavg BLKmax Total ---------- | -------- -------- ------- | -------- -------- -------- -------- ( 8,240) | 57996 57996 1.0 | 25 48 256 2830284 ==================== Device Q2Q Seek Information ==================== DEV | NSEEKS MEAN MEDIAN | MODE ---------- | --------------- --------------- --------------- | --------------- ( 8,240) | 4833 712982.8 0 | 0(2296) ---------- | --------------- --------------- --------------- | --------------- Overall | NSEEKS MEAN MEDIAN | MODE Average | 4833 712982.8 0 | 0(2296) ==================== Device D2D Seek Information ==================== DEV | NSEEKS MEAN MEDIAN | MODE ---------- | --------------- --------------- --------------- | --------------- ( 8,240) | 57996 59415.2 0 | 0(55458) ---------- | --------------- --------------- --------------- | --------------- Overall | NSEEKS MEAN MEDIAN | MODE Average | 57996 59415.2 0 | 0(55458) ==================== Plug Information ==================== DEV | # Plugs # Timer Us | % Time Q Plugged ---------- | ---------- ---------- | ---------------- DEV | IOs/Unp IOs/Unp(to) ---------- | ---------- ---------- ( 8,240) | 0.0 0.0 ==================== Active Requests At Q Information ==================== DEV | Avg Reqs @ Q ---------- | ------------- ( 8,240) | 0.0 ... |
seekwatcher
| #> ./seekwatcher -t [device]_blktrace.* |

※ btt 분석방법
Q2Q — 요청이 블록 계층으로 전송 된 시간
Q2G — 블록 I / O가 큐에서 대기 한 후 요청이 할당 될 때까지 걸리는 시간
G2I — 요청이 할당 된 시간부터 장치의 대기열에 삽입되는 시간까지 소요되는 시간
Q2M — 블록 I / O가 대기열에있는 시간에서 기존 요청과 병합 될 때까지 걸리는 시간
I2D — 요청이 장치의 대기열에 삽입 된 후 장치에 실제로 발행되는 시간까지 걸리는 시간
M2D — 블록 I / O가 종료 요청과 병합 된 시간부터 요청이 장치에 발행 될 때까지 걸리는 시간
D2C — 장치가 요청한 서비스 시간
Q2C — 요청을 위해 블록 레이어에서 보낸 총 시간
※ IO sequence

※ Block IO Tuning Point
1. Q2Q는 Q2C보다 훨씬 큽니다. 즉, 응용 프로그램이 연속적으로 I / O를 발행하지 않습니다. hus, 성능 문제가 I / O 하위 시스템과 전혀 관련이 없을 수도 있습니다.
2. D2C가 매우 높으면 요청을 처리하는 데 시간이 오래 걸립니다. 이는 장치가 단순히 오버로드 된 것 (공유 리소스라는 사실 때문일 수 있음)이거나 장치로 전송 된 작업 부하가 최적화되지 않았기 때문일 수 있습니다.
3. Q2G가 매우 높으면 동시에 대기중인 많은 요청이 있음을 의미합니다. 이는 스토리지가 I / O로드를 유지할 수 없음을 나타낼 수 있습니다.
4. iostat 출력 대기 = Q2C = Q2I + I2D + D2C
5. Q2I + I2D == 스케줄러 시간
6. I2D 시간에는 일정 정렬 대기열 내에서 io의 병합을 개선하는 데 사용되는 플러그 앤 플러그 해제 이벤트 (위에 표시되지 않음)로 인해 많은 추가 시간이 포함될 수 있습니다.
7. D2C 시간은 드라이버 시간, 어댑터 시간, 전송 시간 및 스토리지 서비스 시간 (및 뒤로)을 포함
따라서 D2C / Q2C가 1에 가까워지면 스토리지 구성 요소에 소요되는 시간이 높은 것을 의미합니다.
8. D-> C 시간이 높으면 스위치 카운터 또는 스토리지 박스 자체의 유지 보수 인터페이스와 같은 스토리지의 기본 전송 구조를 검사해야합니다.
'리눅스 커널 프로그래밍' 카테고리의 다른 글
| 리눅스 ftrace란 무엇인가 ??? (3) | 2019.09.06 |
|---|---|
| 리눅스 커널 메모리 (Buffer & Cached) (0) | 2019.09.04 |
| 리눅스 스케줄러 구현 (CFS) (0) | 2019.09.04 |
| 리눅스 프로세스 스케줄러 기본 (0) | 2019.09.04 |
| Load Average 정의 (0) | 2018.08.22 |